目录
- 运输层和网络层的关系
- 多路复用与多路分解
- 无连接的多路复用与多路分解
- 有连接的多路复用与多路分解
一、运输层和网络层的关系
运输层位于应用层和网络层之间,是分层网络体系结构中的重要部分。网络层提供了 主机之间的逻辑通信,而运输层为运行在 不同主机上进程之间提供了逻辑通信。这种差别虽然很细微,但很重要。
二、多路复用与多路分解
因特网为应用层提供了两种截然不同的可用运输层协议。他们分别是UDP、TCP。前者为应用程序提供了一种不可靠的、无连接的服务。而后者则为应用程序提供了一种可靠的、面向连接的服务。TCP和UDP的最基本责任是,将两个端系统间IP的交付服务扩展为运行在端系统上的两个进程之间的服务。这个过程,将主机间交付扩展到进程间交付就被称为 运输层的多路复用与多路分解。
我们知道,应用层的进程通过一个称为 套接字的软件接口向网络发送报文和从网络接收报文: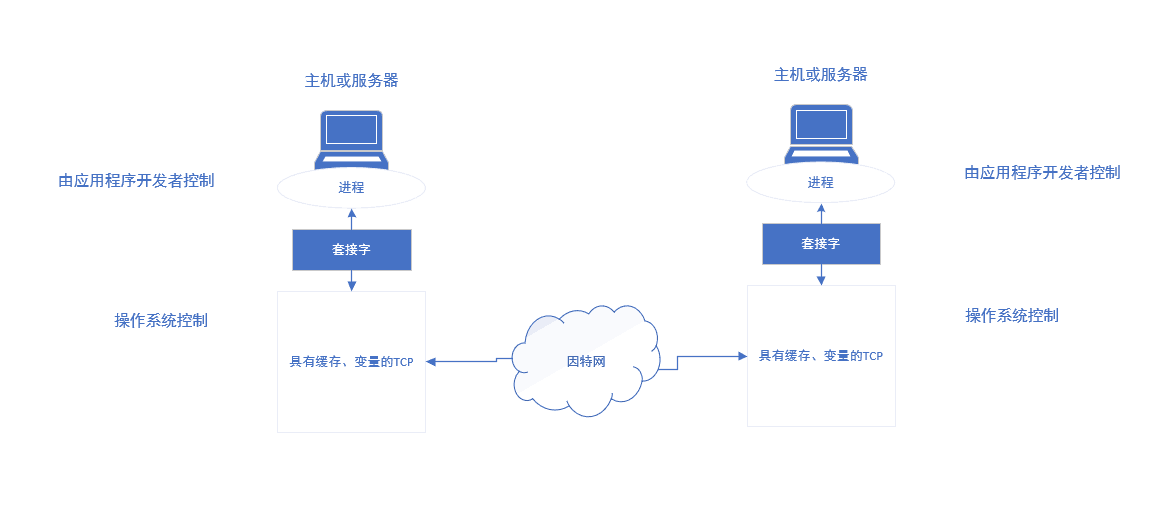
一个进程可以有一个或多个套接字,它相当于从网络向进程传递数据和从进程向网络传递数据的门户。将运输层报文段中的数据交付到正确的套接字的工作我们称为 多路分解。相反的,从不同套接字中收集数据块,并为每个数据块封装上首部信息从而生成报文段,然后将报文段传递到网络层,这被称为 多路复用。
我们理解了运输层的多路复用与多路分解的作用,现在就来看看它们在主机中是如何工作的。思考一下,当我们发送一段报文出去,我们应该如何定位到目的主机的套接字呢?毫无疑问,我们至少需要在报文中加上目的主机的IP地址和目的主机的端口号。在主机上,每当我们创建一个套接字时都会分配到一个端口号(如果不指定,则系统默认分配一个未被使用的)。当报文段到达主机时,运输层检查报文段中的目的端口号,并将其定向到相应的套接字。
三、无连接的多路复用与多路分解
正如上面说的那样,使用UDP时基本过程就和描述的一样。
1 | from socket import * |
这是一段UDP套接字编程的客户端代码。在第五行中,我们利用socket创建了客户的套接字clientSocket。当我们使用这种方式创建时,运输层会自动的为该套接字分配一个端口号。当然,我们也可以自己手动的去指定一个未被使用的端口号:clientSocket.bind(('', 19157))。通过为UDP套接字分配端口号,我们现在能够精确的描述UDP的复用与分解了。
假定在主机A中的一个进程具有UDP端口19157,它要发送一个应用程序数据块给位于主机B中的另一进程,该进程具有UDP端口12000。主机A中的运输层创建一个运输层报文段,其中包含应用程序数据、源端口号、目的端口号(在UDP报文中还有其它两个值,将在UDP传输中讨论)。然后,运输层将得到的报文段传递给网络层。网络层将该报文段封装到一个IP数据报中,并尽力而为的发送给接收主机。如果报文段到达接收主机B,接收主机运输层就检查该报文段中的目的端口号(12000),并将该报文段交付给端口号12000所标识的套接字。
注意到下述事实是重要的:一个UDP套接字是由一个二元组全面标识的,该二元组包含一个目的IP地址和一个目的端口号。因此,如果两个UDP报文段有不同的源IP地址/端口号,但具有相同的目的IP地址和目的端口号,那么这两个报文段将通过相同的目的套接字被定向到相同的目的进程。
四、有连接的多路复用与多路分解
为了理解TCP的多路分解,我们必须更为仔细的研究TCP套接字和TCP连接创建。TCP套接字和UDP套接字之间的一个细微差别是,TCP套接字是由一个四元组来标识的,包含源IP地址、源端口号、目的IP地址和目的端口号。因此,我们可以比较的看出,在使用TCP时,即便是目的IP地址和目的端口号都相同,但源IP地址或端口号不同都不会被定向到同一进程中(除非TCP报文段携带了初始创建连接的请求)。
仍然给出基于TCP套接字编程的客户端/服务器端代码:1
2
3
4
5
6
7
8
9
10
11
12from socket import *
serverName = 'servername'
serverPort = 12000
clientSocket = socket(AF_INEF, SOCK_STREAM)
clientSocket.connect((serverName, serverPort))
sentence = raw_input('input lowercase sentence:')
clientSocket.send(sentence.encode())
modifiedSentence = clientSocket.recv(1024)
print('from server: ', modifiedSentence.decode())
clientSocket.close()
1 | // 服务器端代码 |
由于TCP服务是面向连接的,所以,在第一段代码中,创建了套接字后紧跟着第六行代码向服务器发送了连接请求。这行代码执行完后,执行三次握手,并在客户端和服务器之间创建一条TCP连接。
正如我们看见的服务器端代码,服务器端会有一个“欢迎套接字”,它会在12000号端口上等待来自TCP客户端的连接建立请求。客户端创建一个套接字并发送一个连接请求报文段,该报文段不仅包含TCP首部特定的“连接建立位”,还包含客户端选择的端口号。当运行服务器进程的主机操作系统接收到具有端口号12000的入连接请求报文,它就定位服务器进程,该进程正在端口号12000等待接收连接。服务器的运输层还注意到(虽然我们在应用层的代码中看不到),连接请求报文段中的四个值:该报文段的源端口号、源主机IP地址、目的端口号以及目的IP地址。新创建的连接套接字通过这四个值来标识。所有后续到达的报文段,若它们的这四个值都匹配,就将它们分配到同一套接字中。
服务器主机可以支持很多并行的TCP套接字,每个套接字与一个进程相联系,并由其四元组来标识每个套接字。另外,不得不再次提及的是,连接套接字与进程并不总是有着一一对应的关系。事实上,当今的高性能Web服务器通常只使用一个进程,但是为每个新的客户连接创建一个具有新连接套接字的新线程(线程可以被看做是一个轻量级的子进程)。对于这样一台服务器,在任意给定的时间内都有可能有许多连接套接字连接到相同的进程。
以上内容整理自《计算机网络自顶向下方法》第七版。有问题?发送 issues 给我~