目录
- 概述
- UDP报文段结构
- UDP检验和
一、概述
前面我们讲了,运输层最低限度必须提供一种复用分解服务,以便在网络层与正确的应用级进程之间传递数据。我们这一节所要讨论的,由 RFC 768 定义的UDP就是只做了运输层能做的最少工作。除了复用/分解及少量差错检测外,它几乎没有对IP增加别的东西。UDP从应用进程得到数据,附加上用于多路复用/多路分解的源和目的端口号字段(可以联想上一节介绍的二元组),以及其它的两个小字段(马上就会介绍),然后将形成的报文段交给网络层。
我们知道,由于TCP提供的可靠传输服务,web应用使用的HTTP协议以及FTP等应用层协议都是基于它。现在你也许也想知道,什么样的应用会基于UDP这个无连接的协议呢?要回答这个问题,我想我们需要来看看,UDP相比较于TCP有哪些特点:
- 关于发送什么数据以及何时发送的应用层控制更为精细。我们知道,TCP有一个拥塞控制机制,它让每一个发送方感知当前网络的拥塞程度,从而限制其向连接发送流量的速率。但是,即便是这样,TCP仍然会继续重新发送数据报文段,直到目的主机收到此报文并加以确认。而UDP不同,一旦应用进程将数据传递给它,它就会将此数据打包进UDP报文段并立即将其传递给网络层。
- 无需建立连接。TCP在数据开始传输之前需要建立三次握手,UDP则不需要。也因此,UDP不会引入建立连接的时延。这也可能是DNS运行在UDP上而不是TCP的主要原因。
- 无连接状态。TCP需要在端系统中维护连接状态。此连接状态包括接收和发送缓存、拥塞控制参数以及序号与确认号等参数(后面TCP将介绍)。UDP则不需要维护这些连接状态,也不跟踪这些参数。
- 分组首部开销小。每个TCP报文段都有20字节的首部开销,而UDP仅有8字节。
我们都知道,TCP被广泛应用很大部分是由于其可提供可靠的运输机制。但是需要注意的是,基于UDP的应用也是可能实现可靠数据传输的。这可通过在应用程序自身中建立可靠性机制来完成。谷歌的Chrome浏览器中所使用的QUIC协议就是在UDP之上的应用层协议中实现了可靠性。
UDP也有它适用的场景。下面是流行的因特网应用及其下面的运输层协议:
| 应用 | 应用层协议 | 对应的运输层协议 |
|---|---|---|
| 电子邮件 | SMTP | TCP |
| 远程终端访问 | Telnet | TCP |
| Web | HTTP | TCP |
| 文件传输 | FTP | TCP |
| 远程文件服务器 | NFS | 通常UDP |
| 流式多媒体 | 通常专用 | UDP或TCP |
| 因特网电话 | 通常专用 | UDP或TCP |
| 网络管理 | SNMP | 通常UDP |
| 名字转换 | DNS | 通常UDP |
二、UDP报文段结构
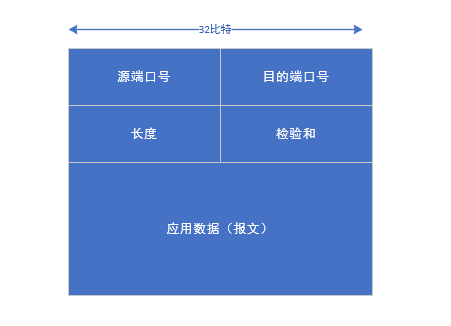
上图是UDP的报文段结构。它的首部只有4个字段,每个字段由两个字节组成。和前面讨论的一样,通过端口号可以使目的主机将应用数据交给运行在目的端系统中的相应进程(多路分解)。长度字段指示了UDP报文中的字节数(包括首部,以字节为单位)。接收方使用这四个字段来检查在该报文段传输过程中是否出现了差错。
三、UDP检验和
UDP检验和提供了差错检测功能。也就是说,检验和用于检验报文段从源到目的过程中是否发生了改变。发送方的UDP对报文段中所有的16比特字的和进行反码运算(先求和再进行反码运算),若求和时发生溢出则回卷。然后将计算得到的值放入报文的检验和字段。
当报文段到达接收端运输层时,接收端将对报文段中的所有字段相加,判断最后得到的和是否为1111111111111111。之后的动作随实现而定。比如有些实现是将受损的报文段交给应用程序并给出警告,但有的实现仅仅只是将出错的报文段丢弃。。。
关于检验和的计算,我们来举个小例子:假定我们由三个16比特的字:
0110011001100000
0101010101010101
1000111100001100
前两个16比特字之和是:1011101110110101
再加上第三个字,得出:0100101011000010
我们注意到最后一次加法有溢出,它要被回卷。而反码的运算就是将所有的0换成1。因此,最后的检验和为1011010100111101。若在传输过程中没有引入差错,显然,四个值相加为1111111111111111。
以上内容整理自《计算机网络自顶向下方法》第七版。有问题?发送 issues 给我~